AMEX
Contents
1.5. 基操#
1.5.1. 合并数据#
df_train = pd.read_parquet("../input/amex-data-integer-dtypes-parquet-format/train.parquet")
labels = pd.read_csv('../input/amex-default-prediction/train_labels.csv')
df_train = df_train.merge(labels, left_on='customer_ID', right_on='customer_ID')
1.5.2. 缺失值可视化#
null_vals = df_train.isna().sum().sort_values(ascending=False)
null_vals[null_vals > 0 ]
plt.figure(figsize=(40,10))
plt.title("Null value count")
plt.xlabel("Columns")
plt.ylabel("Count")
null_vals[null_vals > 0 ].plot(kind="bar");
1.5.3. label数据分布是否balance#
sns.countplot(
df_train["target"].values,
).set_xlabel("Target");
1.6. 数据EDA方法#
1.6.1. 对于这种结构化数据比赛,第一步可以看看有哪些列。#
# a sum view
train_df.dtypes.value_counts()
# a more detailed view
for col in train_df.dtypes.unique():
print(col, train_df.dtypes[train_df.dtypes == col].index.to_list())
print('')
1.6.2. 对于一些数值类型的attributes,我们可以看看具体的取值范围#
desc_df = train_df.describe(include='all')
for col in train_df.columns:
desc_df.loc['unique', col] = train_df[col].nunique()
desc_df.loc['unique'] = desc_df.loc['unique'].astype(int)
plt.figure(figsize=(20,4))
desc_df.loc['unique'].plot(kind='bar')
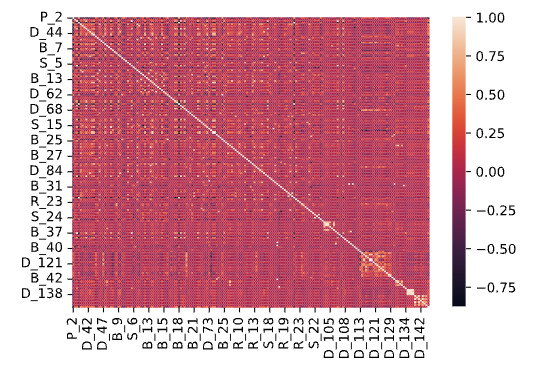
1.6.3. 特征之间的相关性#
Note
热力图不要只看某个pixel格子,而是要看特征成组的情况。
可以用corr_agg.loc[‘label’].abs().plot(kind=’bar’)来获得所有attributes和label之间的关系。
寻找周期性,来看主办方是否有特意按照某种模式储存
mean_agg = train_df.groupby('customer_ID').mean().reset_index()
corr_agg = mean_agg.corr()
sns.heatmap(corr_agg)
plt.figure(figsize=(15, 4))
corr_agg.loc['label'].abs().plot(kind='bar')
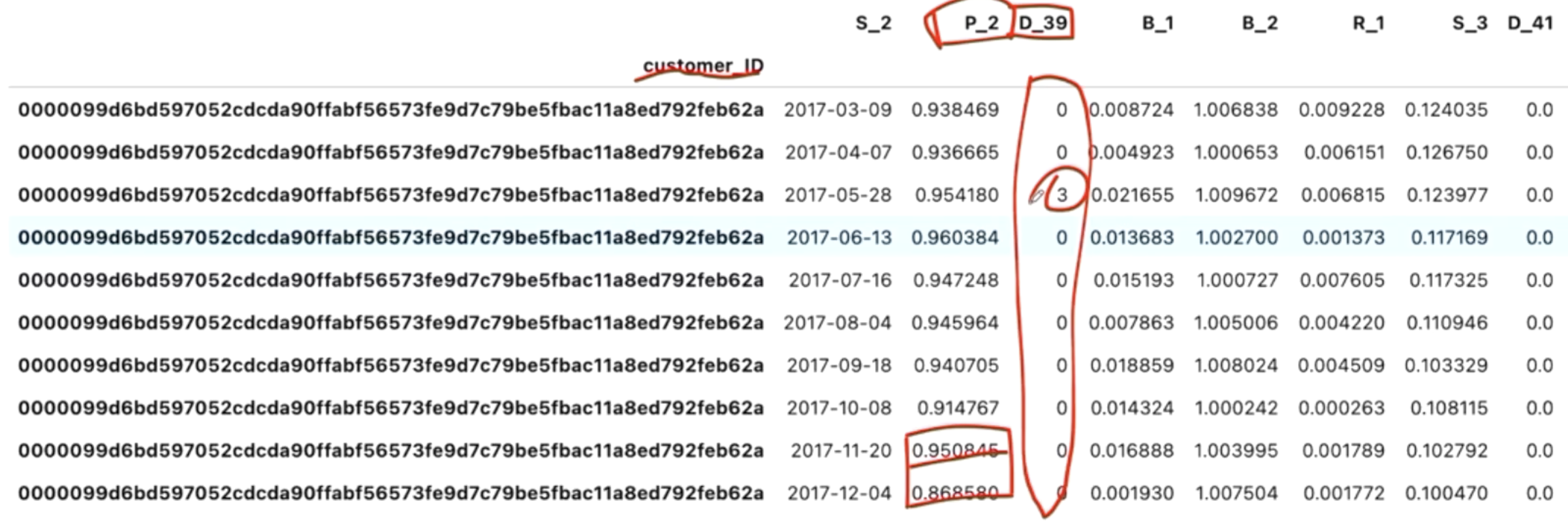
1.6.4. 对于group by的数据,看看分布#
rand_customers = np.unique(df_train["customer_ID"])[:100] # for 100 customers
id_counts = df_train[df_train["customer_ID"].isin(rand_customers)].groupby("customer_ID").agg("count")
plt.figure(figsize=(20,10))
id_counts["S_2"].plot(kind='bar');
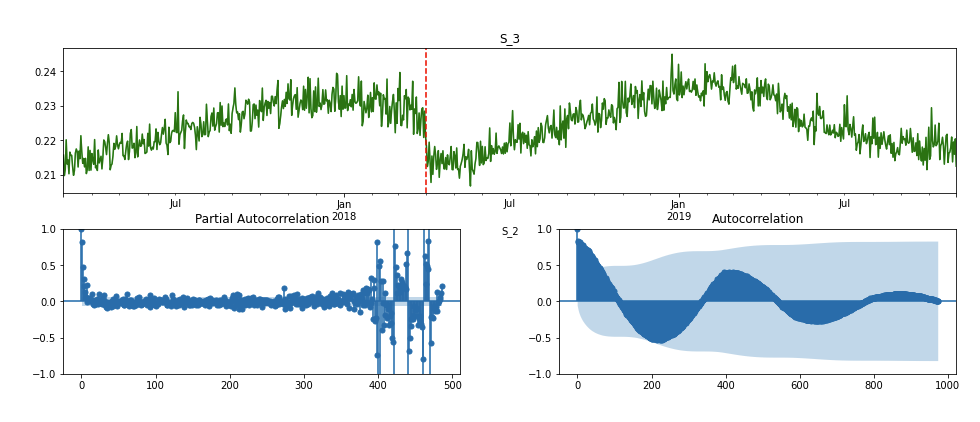
1.6.5. 大量的特征有seasonal patterns时#
这可能会在很多方面影响模型:比如数据漂移和对未见过的数据表现不好。另外,即使是简单的特征工程也可能不太准确–如果特征有稳定的正向趋势,那么最大值将更接近于最后一次付款。我们可以考虑在每日水平上对数据进行规范化,以避免这些错误。这也可能为特征提取打开额外的维度:例如,我们可以使用季节性或趋势特征作为额外的特征。
计算每一天每个特征的平均值,从而得出每个特征的单变量时间序列。只有当最大的自相关成分超过阈值(0.6)时才绘制.
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import acf, pacf
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import gc
import numpy as np
import pandas as pd
import os
train_agg = pd.read_parquet('../train.parquet').assign(S_2=lambda dx: pd.to_datetime(dx.S_2)).groupby('S_2').mean()
end_of_train = pd.to_datetime(train_agg.index).max()
test_agg = []
for cols2use in train_agg.columns.values.reshape(-1, 47):
test_agg.append(pd.read_parquet('../test.parquet', columns=cols2use.tolist() + ['S_2']).assign(S_2=lambda dx: pd.to_datetime(dx.S_2)).groupby('S_2').mean())
test_agg = pd.concat(test_agg, axis=1)
agg_data = pd.concat([train_agg, test_agg])
for first_letter in list(set([col.split('_')[0] for col in agg_data.columns])):
break
for first_letter in list(set([col.split('_')[0] for col in agg_data.columns])):
for feature_name in agg_data.columns:
if feature_name[0] != first_letter:
continue
s = agg_data.loc[:, feature_name]
max_acf = np.abs(acf(s, nlags=agg_data.index.size - 1))[1:].max()
if max_acf > 0.6:
print(feature_name) # for Ctrl + F
fig = plt.figure(figsize=(16, 6))
sub_pacf = fig.add_subplot(2,2,4)
sub_acf = fig.add_subplot(2,2,3)
mn = fig.add_subplot(2,2,(1,2))
plot_pacf(s, lags=agg_data.index.size/2-1, ax=sub_acf)
plot_acf(s, lags=agg_data.index.size-1, ax=sub_pacf)
s.plot(color='green', ax=mn)
mn.axvline(end_of_train, color='red', linestyle='--')
mn.set_title(feature_name)
plt.subplots_adjust(wspace= 0.25, hspace= 0.25)
plt.show()
1.6.6. 如果attribute名称可以找规律的话,看看分布#
var_count = {}
for col in df_train.columns :
if col.startswith("S_"):
var_count["Spend variables"] = var_count.get("Spend variables", 0) + 1
if col.startswith("D_"):
var_count["Deliquency variables"] = var_count.get("Deliquency variables", 0) + 1
if col.startswith("B_"):
var_count["Balance variables"] = var_count.get("Balance variables", 0) + 1
if col.startswith("R_"):
var_count["Risk variables"] = var_count.get("Risk variables", 0) + 1
if col.startswith("P_"):
var_count["Payment variables"] = var_count.get("Payment variables", 0) + 1
plt.figure(figsize=(15,5))
sns.barplot(x=list(var_count.keys()), y=list(var_count.values()));
1.6.6.1. 针对此类特征的可视化(例如他们对应labels的分布)#
payment_vars = [col for col in df_train.columns if col.startswith("P_")]
corr = df_train[payment_vars+["target"]].corr()
sns.heatmap(corr, annot=True, cmap="Purples");
fig, axes = plt.subplots(1,3, figsize=(20,5))
axes = axes.ravel()
for i, col in enumerate(payment_vars) :
sns.histplot(data = df_train, x = col, hue='target', ax=axes[i])
fig.suptitle("Distribution of Payment Variables w.r.t target")
fig.tight_layout()
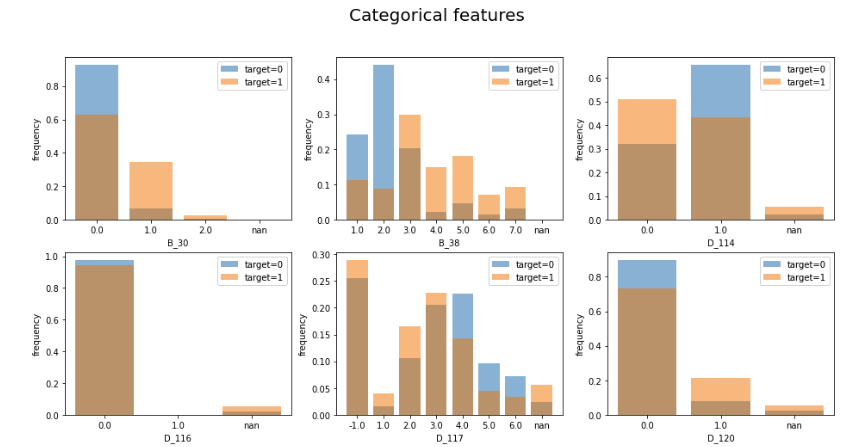
1.6.7. 针对cat特征对应labels的可视化#
cat_features = ['B_30', 'B_38', 'D_114', 'D_116', 'D_117', 'D_120', 'D_126', 'D_63', 'D_64', 'D_66', 'D_68']
plt.figure(figsize=(16, 16))
for i, f in enumerate(cat_features):
plt.subplot(4, 3, i+1)
temp = pd.DataFrame(train[f][train.target == 0].value_counts(dropna=False, normalize=True).sort_index().rename('count'))
temp.index.name = 'value'
temp.reset_index(inplace=True)
plt.bar(temp.index, temp['count'], alpha=0.5, label='target=0')
temp = pd.DataFrame(train[f][train.target == 1].value_counts(dropna=False, normalize=True).sort_index().rename('count'))
temp.index.name = 'value'
temp.reset_index(inplace=True)
plt.bar(temp.index, temp['count'], alpha=0.5, label='target=1')
plt.xlabel(f)
plt.ylabel('frequency')
plt.legend()
plt.xticks(temp.index, temp.value)
plt.suptitle('Categorical features', fontsize=20, y=0.93)
plt.show()
del temp
1.6.8. 时序可视化#
观察每种attribute的日期分布情况
temp = pd.concat([train[['customer_ID', 'S_2']], test[['customer_ID', 'S_2']]], axis=0)
temp.set_index('customer_ID', inplace=True)
temp['last_month'] = temp.groupby('customer_ID').S_2.max().dt.month
last_month = temp['last_month'].values
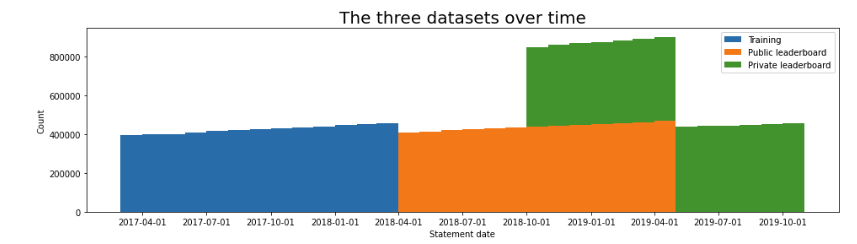
plt.figure(figsize=(16, 4))
plt.hist([temp.S_2[temp.last_month == 3], # ending 03/18 -> training
temp.S_2[temp.last_month == 4], # ending 04/19 -> public lb
temp.S_2[temp.last_month == 10]], # ending 10/19 -> private lb
bins=pd.date_range("2017-03-01", "2019-11-01", freq="MS"),
label=['Training', 'Public leaderboard', 'Private leaderboard'],
stacked=True)
plt.xticks(pd.date_range("2017-03-01", "2019-11-01", freq="QS"))
plt.xlabel('Statement date')
plt.ylabel('Count')
plt.title('The three datasets over time', fontsize=20)
plt.legend()
plt.show()
for f in [ 'B_29', 'S_9','D_87']:#, 'D_88', 'R_26', 'R_27', 'D_108', 'D_110', 'D_111', 'B_39', 'B_42']:
temp = pd.concat([train[[f, 'S_2']], test[[f, 'S_2']]], axis=0)
temp['last_month'] = last_month
temp['has_f'] = ~temp[f].isna()
plt.figure(figsize=(16, 4))
plt.hist([temp.S_2[temp.has_f & (temp.last_month == 3)], # ending 03/18 -> training
temp.S_2[temp.has_f & (temp.last_month == 4)], # ending 04/19 -> public lb
temp.S_2[temp.has_f & (temp.last_month == 10)]], # ending 10/19 -> private lb
bins=pd.date_range("2017-03-01", "2019-11-01", freq="MS"),
label=['Training', 'Public leaderboard', 'Private leaderboard'],
stacked=True)
plt.xticks(pd.date_range("2017-03-01", "2019-11-01", freq="QS"))
plt.xlabel('Statement date')
plt.ylabel(f'Count of {f} non-null values')
plt.title(f'{f} non-null values over time', fontsize=20)
plt.legend()
plt.show()